相关文章

Golang | Leetcode Golang题解之第80题删除有序数组中的重复项II
题目: 题解:
func removeDuplicates(nums []int) int {n : len(nums)if n < 2 {return n}slow, fast : 2, 2for fast < n {if nums[slow-2] ! nums[fast] {nums[slow] nums[fast]slow}fast}return slow
}
编程日记
2024/10/21 7:17:21

强化学习的优化策略PPO和DPO
DPO
DPO(直接偏好优化)简化了RLHF流程。它的工作原理是创建人类偏好对的数据集,每个偏好对都包含一个提示和两种可能的完成方式——一种是首选,一种是不受欢迎。然后对LLM进行微调,以最大限度地提高生成首选完成的可能性,并最大限…
编程日记
2024/10/21 7:23:04

路径优化算法 | 基于遗传算法求解多式联运运输问题
内容
多式联运运输问题是一个复杂的组合优化问题,其中涉及到多种不同的运输方式和路径选择。遗传算法是一种常用的启发式优化算法,可以用于求解这类问题。
下面是基于遗传算法求解多式联运运输问题的一般步骤:
确定问题的数学模型:将多式联运运输问题转化为数学模型,包…
编程日记
2024/10/21 14:14:42
【scikit-learn005】支持向量机(Support Vector Machines, SVM)ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架支持向量机(Support Vec…
编程日记
2024/10/21 3:23:28

21【Aseprite 作图】画白菜
1 对着参考图画轮廓 2 缩小尺寸 变成这样 3 本来是红色的描边,可以通过油漆桶工具(取消 “连续”),就把红色的轮廓线,变成黑色的
同时用吸管工具,吸取绿色和白色,用油漆桶填充颜色 4 加上阴影…
编程日记
2024/10/19 11:38:30

Linux·基本指令
从本节开始将新开一个关于Linux操作系统的板块,其实Linux也没什么太神秘的,就是一个操作系统(OS)嘛,跟Windows操作系统是一个概念,只不过Windows中的大部分操作都是用光标点击来进行人机交互,但是Linux是通过输入命令行…
编程日记
2024/10/19 5:29:16
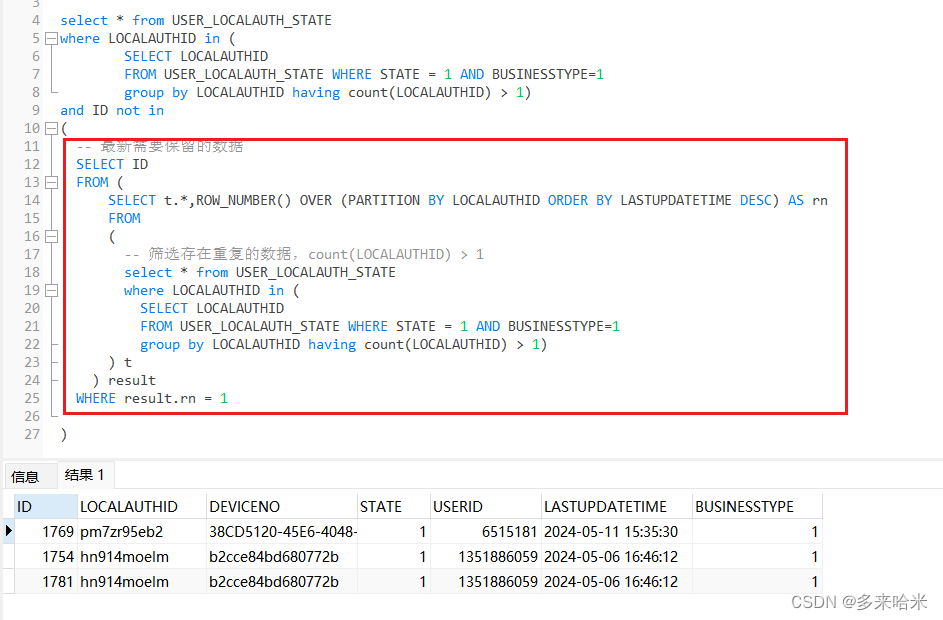
oracle多条重复数据,取最新的
1、原理讲解-可直接看2
筛选出最新的
SELECT *
FROM ( SELECT t.*, ROW_NUMBER() OVER (PARTITION BY LOCALAUTHID ORDER BY LASTUPDATETIME DESC) AS rn FROM USER_LOCALAUTH_STATE t
) t
WHERE t.rn 1;
解释:
这个序号是基于[LOCALAUTHID]字段进行分…
编程日记
2024/10/19 9:35:14
Cesium学习_-着色器
着色器GLSL
CesiumJS PrimitiveAPI 高级着色入门 - 从参数化几何与 Fabric 材质到着色器 - 下篇 - 知乎 明确一个定义,在 Primitive API 中应用着色器,实际上是给 Appearance 的 vertex- ShaderSource、fragmentShaderSource 或 Material 中的 fabric.…
编程日记
2024/10/21 5:16:03

